|
Claude Grasland Université Paris VII / UFR GHSS - Deug de Géographie- 1ere année / 2nd Semestre (revisé en 2003)
|
|
|
|
|
|
|
|
|
INTRODUCTION :
1. LA DISCRETISATION
1.1 Dichotomie (2 modalités)
2. LA TRANSFORMATION EN
RANGS
2.1 Définition des rangs en statistique
3. LA TRANSFORMATION EN
INDICE
3.1 Indices fondés sur une valeur centrale
4. LA STANDARDISATION
4.1 Centrage et réduction
5. UNE APPLICATION : LA MATRICE BERTIN
5.1 Du tableau élémentaire au tableau standardisé
5.2 Regroupement des colonnes (étude des corrélations)
5.3 Regroupement des lignes (classification)
| Pour obtenir un cours de statistique détaillé, mais non centré sur la géographie, cliquez ici. |
La comparaison de plusieurs caractères quantitatifs ou bien celle de caractères quantitatifs et qualitatifs, n'est généralement pas possible à partir du tableau élémentaire car les caractères à comparer peuvent avoir :
- des unités de mesure différentes.
- des ordres de grandeur différents (valeurs centrales)
- des dispersions différentes (paramètres de dispersion).
- des modalités qualitatives
Tableau 1 : Indicateurs
de santé de 9 pays développés en 1995
| Pays |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Canada |
|
|
|
|
| France |
|
|
|
|
| Norvège |
|
|
|
|
| Etats-Unis |
|
|
|
|
| Finlande |
|
|
|
|
| Pays-Bas |
|
|
|
|
| Japon |
|
|
|
|
| Nouvelle-Zélande |
|
|
|
|
| Suède |
|
|
|
|
| Moyenne |
|
|
|
|
| écart-type |
|
|
|
|
| Min |
|
|
|
|
| Médiane |
|
|
|
|
| max |
|
|
|
|
Source : Rapport sur le développement humain, 1998, p. 210
=> Dans le tableau 1,
il est difficile de comparer les valeurs des différentes colonnes
car elles ont des ordres de grandeur différent (V1 et V2) ou des
unités de mesure différentes (V2,V3,V4).
Il est donc généralement
nécessaire de transformer les caractères quantitatifs à
étudier avant de pouvoir les comparer les uns aux autres. Quatre
types de transformations sont présentées.
1) La discrétisation,
La discrétisation consiste à transformer un caractère quantitatif continu en caractère discret. On parle de dichotomie lorsque le caractère discret n'a que deux modalités.
* dichotomie (2 modalités)
On fixe un seuil Xref qui définit la limite entre les valeurs fortes et faibles de Xi. Xref peut être une valeur centrale (moyenne, médiane) ou bien une valeur qui possède une signification particulière pour l'interprétation. On crée la variable qualitative X' ayant deux modalités (+ ou - ) selon procédure suivante :
X'i = + si X i est supérieur à Xref
X' i = -
si X i est inférieur ou égal à Xref
Tableau 2 : Discrétisation en 2
classes fondées sur la médiane
| Pays |
|
|
|
|
|
| Canada |
|
|
|
|
|
| France |
|
|
|
|
|
| Norvège |
|
|
|
|
|
| Etats-Unis |
|
|
|
|
|
| Finlande |
|
|
|
|
|
| Pays-Bas |
|
|
|
|
|
| Japon |
|
|
|
|
|
| Nouvelle-Zélande |
|
|
|
|
|
| Suède |
|
|
|
|
|
=> On repère immédiatement les pays situés au dessus ou au dessous de la médiane pour chacun des critères. On peut également dénombrer le nombre de valeurs + ou - si les indicateurs sont de même nature (ici, des pathologies). On remarque que le Canada et la France ont des valeurs élevées pour 4 pathologies alors que la Suède et la Finlande ont régulièrement des valeurs faibles.
* autres méthodes de discrétisation :
On n'est évidemment pas obligé de se limiter à deux classes et l'on peut construire des discrétisations en 3, 4, 5 classes ou plus, en utilisant les méthodes de partition qui ont été apprises dans les chapitres précédents (effectifs égaux, amplitudes égales, utilisation de la moyenne et de l'écart-type, etc.). La seule règle à respecter est d'utiliser la même méthode de discrétisation pour tous les caractères du tableau, faute de quoi les comparaisons ne seraient pas valables.
2) La transformation en rangs
Chaque modalité du caractère X i est transformée en une modalité d'un caractère qualitatif ordinal X' i qui indique le rang pris par l'élément Xi dans la série X1..Xn (n étant le nombre d'éléments de l'ensemble observé).
X'i => rang de X i dans la distribution statistique de X
La méthode ne pose pas de problème mais il faut faire attention à deux choses :
1) l'ordre de classement (croissant ou décroissant) doit être spécifié et être a priori le même pour les différents caractères que l'on veut comparer
2) lorsqu'il y a des ex-aequo, on leur attribue comme rang la moyenne des places qu'ils auraient occupées s'ils avaient été à la suite les uns des autres. On reprend ensuite le classement après les rangs virtuellement occupés. Si les rangs sont correctement construits, leur somme doit être égale à n(n+1)/2 .
La méthode des rangs donne de bons résultats mais il faut être conscient du fait que
| Pays |
|
|
|
|
moy. Rang |
| Canada |
|
|
|
|
|
| France |
|
|
|
|
|
| Norvège |
|
|
|
|
|
| Etats-Unis |
|
|
|
|
|
| Finlande |
|
|
|
|
|
| Pays-Bas |
|
|
|
|
|
| Japon |
|
|
|
|
|
| Nouvelle-Zélande |
|
|
|
|
|
| Suède |
|
|
|
|
|
| Somme |
|
|
|
|
45
|
Lorsque l'on veut comparer deux caractères quantitatifs ayant des ordres de grandeur ou des unités de mesure différentes, on peut les transformer en indices. Il existe deux méthodes, selon que l'on construit l'indice par rapport à une valeur de référence ou par rapport à un intervalle.
* Indices fondés sur une valeur de référence
X'i = B. Xi / Xref
Le cas le plus fréquent est de choisir une valeur centrale comme base de l'indice ("indice 100 = moyenne" ou "indice 100 = médiane"). Dans le cas particulier des séries chronologiques (X1 . Xt désigne la valeur de X à différentes dates 1.t) on choisit souvent une année particulière (début, fin, milieu de la période, .) comme référence et on précise alors "Indice 100 = valeur de X au temps t".
Tableau 4 : transformation
en indices 100 = moyenne
| Pays |
|
|
|
|
moyenne |
| Canada |
|
|
|
|
|
| France |
|
|
|
|
|
| Norvège |
|
|
|
|
|
| Etats-Unis |
|
|
|
|
|
| Finlande |
|
|
|
|
|
| Pays-Bas |
|
|
|
|
|
| Japon |
|
|
|
|
|
| Nouvelle-Zélande |
|
|
|
|
|
| Suède |
|
|
|
|
|
| Moyenne |
|
|
|
|
|
* Indices fondés sur un intervalle de référence
On peut également utiliser une standardisation fondée sur l'emploi d'un intervalle de référence comprenant une valeur minimale (Xmin) et une valeur maximale (Xmax) Ces valeurs maximales et minimales peuvent être soit celles de la distribution proprement dite, soit celles du phénomène étudié (l'intervalle est dans ce cas plus large que les valeurs réellement observées de la distribution).
L'opération consiste à mesurer la position des valeurs Xi sur l'intervalle défini par les maximales et minimales, de manière à aboutir à une nouvelle variable X'i strictement comprise entre 0 (minimum) et 1 (maximum) :
X'i = (Xi - Xmin) / (Xmax - Xmin)
Cette méthode est notamment utilisée par les Nations Unies pour définir l'indicateur de développement humain (IDH) qui exprime le degré de satisfaction des besoins essentiels (longévité, scolarisation, revenus) sur des échelles comprises entre 0 (pays les plus pauvres) et 1 (pays où les besoins minimums sont pleinement satisfaits).
Tableau 5 : transformation en indices fondées sur le minimum et le maximum
| Pays |
|
|
|
|
Moyenne |
| Canada |
|
|
|
|
|
| France |
|
|
|
|
|
| Norvège |
|
|
|
|
|
| Etats-Unis |
|
|
|
|
|
| Finlande |
|
|
|
|
|
| Pays-Bas |
|
|
|
|
|
| Japon |
|
|
|
|
|
| Nouvelle-Zélande |
|
|
|
|
|
| Suède |
|
|
|
|
|
4) La standardisation
La standardisation est sans doute la transformation la plus efficace quand on veut comparer deux variables quantitatives. Elle consiste à opérer une double transformation de centrage et de réduction.
Centrage : L'opération
de centrage consiste à transformer un caractère X en un caractère
X' qui exprime les écarts positifs ou négatifs par rapport
à une valeur de référence qui est la moyenne arithmétique
de la distribution
X' i = X i / s(X)
Dans la plupart des cas, on utilise l'écart-type
pour effectuer la réduction.
Standardisation : une variable standardisée
(on dit aussi centrée-réduite) a été centrée
par la moyenne et réduite par l'écart-type :
X' i = (X i - moyenne de X)/s(X)
Une variable standardisée
(centrée-réduite) possède une moyenne de 0 et un écart
type de 1. Elle exprime l'écart
d'un élément de la distribution à la moyenne, mesuré
en écarts-types. L'unité de mesure de la variable d'origine
a donc disparu et il est toujours possible de comparer deux variables standardisées.
L'interprétation des valeurs standardisées
se fait par rapport au référentiel constitué par la
courbe de Gauss (loi Normale) qui a été présentée
dans le chapitre précédent (STAT.4).
Compte tenu des probabilités associées aux déviations
par rapport à la moyenne mesurées en écart-type, on
peut proposer une grille d'interprétation qualitative des valeurs
standardisées :
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Un tableau de valeur standardisées
permet de repérer très facilement les valeurs exceptionnelles
(inférieures à -2 ou supérieures à +2). Avec
un peu d'habitude, il permet également de commenter très
rapidement la position de chaque élément par rapport à
un grand nombre de caractères.
| Pays |
|
|
|
|
moyenne |
| Canada |
|
|
|
|
|
| France |
|
|
|
|
|
| Norvège |
|
|
|
|
|
| Etats-Unis |
|
|
|
|
|
| Finlande |
|
|
|
|
|
| Pays-Bas |
|
|
|
|
|
| Japon |
|
|
|
|
|
| Nouvelle-Zélande |
|
|
|
|
|
| Suède |
|
|
|
|
|
| moyenne |
|
|
|
|
|
| écart-type |
|
|
|
|
|
5) Une application : la matrice BERTIN
Mises au point à l'époque où les méthodes statistiques étaient encore peu employées en sciences sociales et où les ordinateurs étaient difficiles d'accès, les méthodes de traitement graphique de l'information mises au point par Jacques Bertin ont été en parties supplantées par d'autres outils (analyse factorielle, classification automatique, ...). Elles demeurent cependant encore très utiles pour apprendre la statisique bivariée ou multivariée et pour présenter les résultats d'une analyse statistique. On se limitera ici à la présentation de la méthode d'analyse de la « Matrice Bertin » qui consiste à transformer un tableau numérique en tableau graphique pour ensuite examiner les relations entre les lignes et les relations entre les colonnes. Pour plus de détails, voir :
A titre d'exemple, nous allons étudier un tableau relatif à la situation démographique en 1999 des 15 pays issus de l'Union Soviétique.
Liste des variables :
JEU = part des 0-14 ans dans la population totale (en % de la pop. Totale)
VIE = part des + de 60 ans dans la population totale (en % de la pop. Totale)
TMI = taux de mortalité infantile (en décés de 0-1 an p. 1000 naissances)
DEN = Densité de population (en hab./km2)
URB = Taux d'urbanisation (en % de la pop. Totale)
ISF = Indice synthétique de fécondité (en nombre d'enfants par femme)
1ere étape : passage du tableau brut au tableau standardisé
|
|
JEU |
VIE |
TMI |
DEN |
URB |
ISF |
|
|
JEU |
VIE |
TMI |
DEN |
URB |
ISF |
|
Arm |
27 |
8 |
15 |
127 |
70 |
1,50 |
|
Arm |
-0,1 |
-0,3 |
-0,5 |
1,9 |
0,6 |
-0,5 |
|
Aze |
33 |
6 |
20 |
89 |
57 |
2,10 |
|
Aze |
0,6 |
-0,9 |
0,2 |
0,9 |
-0,3 |
0,4 |
|
Bié |
20 |
13 |
11 |
49 |
74 |
1,30 |
|
Bié |
-0,9 |
1,0 |
-1,1 |
-0,2 |
0,9 |
-0,8 |
|
Est |
19 |
14 |
10 |
31 |
74 |
1,20 |
|
Est |
-1,0 |
1,2 |
-1,2 |
-0,6 |
0,9 |
-0,9 |
|
Géo |
24 |
11 |
15 |
77 |
61 |
1,30 |
|
Géo |
-0,5 |
0,4 |
-0,5 |
0,6 |
0,0 |
-0,8 |
|
Kaz |
30 |
7 |
25 |
6 |
62 |
1,80 |
|
Kaz |
0,2 |
-0,6 |
0,8 |
-1,3 |
0,1 |
-0,1 |
|
Kir |
37 |
6 |
26 |
24 |
40 |
2,80 |
|
Kir |
1,1 |
-0,9 |
1,0 |
-0,8 |
-1,5 |
1,3 |
|
Let |
19 |
14 |
15 |
37 |
74 |
1,10 |
|
Let |
-1,0 |
1,2 |
-0,5 |
-0,5 |
0,9 |
-1,0 |
|
Lit |
21 |
13 |
9 |
57 |
75 |
1,40 |
|
Lit |
-0,8 |
1,0 |
-1,3 |
0,1 |
1,0 |
-0,6 |
|
Mol |
26 |
9 |
20 |
126 |
55 |
1,70 |
|
Mol |
-0,2 |
-0,1 |
0,2 |
1,9 |
-0,4 |
-0,2 |
|
Ouz |
40 |
4 |
23 |
55 |
42 |
3,20 |
|
Ouz |
1,4 |
-1,4 |
0,6 |
0,0 |
-1,3 |
1,9 |
|
Rus |
20 |
13 |
17 |
9 |
78 |
1,20 |
|
Rus |
-0,9 |
1,0 |
-0,3 |
-1,2 |
1,2 |
-0,9 |
|
Tad |
44 |
4 |
25 |
43 |
33 |
3,20 |
|
Tad |
1,9 |
-1,4 |
0,8 |
-0,3 |
-2,0 |
1,9 |
|
Tur |
40 |
4 |
38 |
10 |
46 |
2,60 |
|
Tur |
1,4 |
-1,4 |
2,6 |
-1,2 |
-1,1 |
1,0 |
|
Ukr |
19 |
14 |
14 |
83 |
73 |
1,30 |
|
Ukr |
-1,0 |
1,2 |
-0,7 |
0,7 |
0,8 |
-0,8 |
|
moy |
27,9 |
9,3 |
18,9 |
54,7 |
60,9 |
1,8 |
|
moy |
0,0 |
0,0 |
0,0 |
0,0 |
0,0 |
0,0 |
|
ect |
8,5 |
3,9 |
7,4 |
37,7 |
14,3 |
0,7 |
|
ect |
1,0 |
1,0 |
1,0 |
1,0 |
1,0 |
1,0 |
2e étape : passage du tableau standardisé au tableau graphique
On remplace les valeurs standardisées fortes et faibles par des trames allant du clair au foncé. Ici, on a utilisé les seuils min, moy-1 ect, moy, moy + 1 ect., max pour définir les quatre classes visuelles.
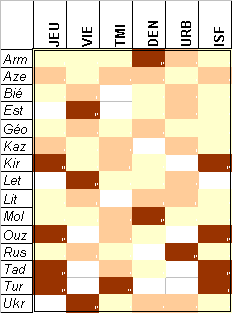
3e étape : Regroupement des colonnes
On réordonne les colonnes de la matrice pour rapprocher les colonnes qui se ressemblent et séparer celles qui sont différentes. On repère ainsi des corrélations positives (ex. JEU & TMI ou URB & VIE), des corrélations négatives (ex. TMI & URB) et des absences de corrélation (ex. VIE & DEN).
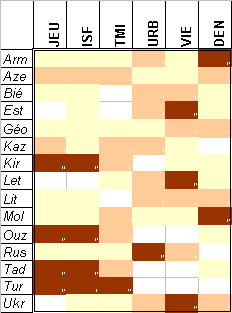
4e étape : Regroupement des lignes
On réordonne les lignes de la matrice pour rapprocher les individus qui se ressemblent et séparer ceux qui sont différentes. On repère ainsi des groupes d'individus ressemblants (ex. Tur-Ouz-Tad-Kir ) ou absolument opposés (Tur & Ukr)

5e étape : Synthèse des résultats
On peut cartographier les résultats de la typologie puis fournir une interprétation générale du tableau en combinant l'étude des lignes et des colonnes.
