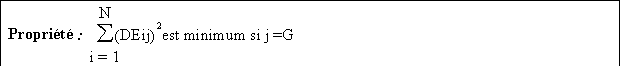
|
Analyse spatiale et modélisation des phénomènes géographiques Claude Grasland Université Paris VII / UFR GHSS - Licence de Géographie / Année 2000-2001 / 1er Semestre
|
L'acte géographique élémentaire, le
point de départ de toute démarche d'analyse spatiale, consiste
à localiser des objets ou des événements à
la surface de la Terre. Cet acte qui paraît anodin à l'heure
des GPS a longtemps constitué une difficulté majeure puisque,
si la mesure de la latitude a été obtenue très
tôt avec une bonne approximation grâce au sextant, celle de
la longitude posait des difficultés beaucoup plus redoutables
(Cf. le roman d'U. Eco, L'île du jour d'avant). La difficulté
de la mesure des longitudes était lié au fait que sa mesure
dépendait d'un troisième paramètre de localisation,
le temps. En effet la localisation d'un objet élémentaire
à la surface de la Terre dépend d'un triplet (x,y,t)
qui suppose l'existence d'un repère universel dans le temps et dans
l'espace. Si l'on ajoute que la vie humaine ne se déroule pas sur
une surface mais dans un volume qui possède une certaine épaisseur,
il convient d'ajouter une dernière dimension qui est l'altitude
(z). Au total c'est donc un quadruplet (x,y,z,t) qui permet de définir
la localisation précise d'un objet ou d'un événement
à la surface de la terre.
Un second problème crucial pour la géographie est
la distinction qu'il faut opérer entre points et lieux et
les difficultés qu'entraîne l'assimilation des seconds aux
premiers.
Définition : un point de la surface terrestre est une position définie précisément par ses trois coordonnées de longitude, latitude et altitude. Un point est un objet abstrait de surface nulle.
Exemple :
- Le Pôle Nord : (90°00'N, ***, 0m)
- Le sommet du Mont Blanc : (46°55'N,6°52'E,4807m)
Définition : un lieu est une portion plus ou moins bien définie de la surface terrestre, de superficie non nulle, généralement dotée d'un nom propre.
Exemple :
- L'Arctique
- Le Massif du Mont-Blanc
Un lieu possédant une surface non nulle, il peut être caractérisé
par différents attributs (surface, population, nombre d'entreprise,
quantité de forêts,
) qui définissent son poids pour
un critère donné.
- un point a une surface nulle alors qu'un lieu a une surface non nulle.
- un lieu peut contenir des objets alors qu'un point ne peut par définition
rien contenir.
On classe souvent les lieux en points, lignes et aires. Il s'agit en
fait d'une abstraction car tout lieu possède une superficie non
nulle.
Des unités géographiques peuvent être assimilées
à des points (ou des lignes) lorsque l'échelle d'observation
l'autorise : pour une étude du système urbain français,
on négligera la superficie des villes et chacune sera assimilée
à un point correspondant au centre de gravité de la population
ou de la superficie de la ville, voire à celui de sa commune-centre.
De la même manière, une commune ou un département pourra
être assimilée à un lieu, celui des coordonnées
de son "chef-lieu" (qui comme son nom l'indique est le lieu de référence
de l'unité spatiale).
Le point de départ de l'analyse consiste donc en un ensemble de N points 1..i..N décrits par leurs coordonnées de position (Xi, Yi, Zi, Ti). Dans ce chapitre, on négligera les différences d'altitudes (Zi) et on supposera que la situation observée correspond à la distribution à une même date (T), de sorte que l'on partira uniquement d'un tableau de coordonnées (X,Y).
On examinera toutefois le cas où le semis de point décrit un ensemble de lieux dotés d'une population P, de sorte que chaque lieu sera muni d'un poids Pi indiquant le nombre d'individus de la population P qu'il contient. Le tableau étudié sera alors du type (X,Y,P) et correspondra à la distribution d'une population
Situation absolue et situation relative
L'évaluation de la position d'un lieu peut se faire de deux façons différentes :
| Pour expliquer l'importance d'une ville comme Lyon,
on recours souvent à l'analyse de son site et de sa situation. Les
caractéristiques du site (présence d'eau, topographie, gué,
...) indiquent généralement quels avantages initiaux ont
conduit à la fondation de la ville en un lieu donné. Cependant,
il est rare que ce type d'explication soit suffisant, car beaucoup de lieux
possédant les mêmes avantages de site n'ont pas donné
naissance à des villes importantes.
Un second type d'explication réside dans l'appréhension de la situation relative, c'est à dire des contacts potentiels et des relations de complémentarité ou de concurrence. Ainsi, on peut montrer que la situation de Lyon au croisement de 3 régions naturelles (Monts du Lyonnais, Dombes, Dauphiné) en a fait très tôt un point d'échange régional. On peut montrer aussi que sa situation de carrefour sur les axes Nord-Sud et Est-Ouest lui assure des relations de longue portée qui ont pu se renouveler avec les différents types de transport (eau, route, rail, ...). On peut rappeler que Lyon, située longtemps aux frontières du Royaume de France jouait le rôle de point d'échange privilégiée, de base militaire avancée, etc. Enfin, on peut montrer que sonb éloignement de Paris lui a permis de subir une concurrence moindre que d'autres villes comme Rouen, ce qui a assuré sa promotion durable. |
D'une manière générale, les caractéristiques
de situation absolue ont une portée explicative plus réduite
que les caractéristiques de situation relative. Les premières
expliquent les fondations initiales, mais au fur et à mesure que
les échanges se développent, ce sont les caractéristiques
de situation relative qui deviennent déterminantes.
- Les coordonnées absolues (on dit aussi géographique) correspondent à la localisation à la surface de l'ellipsoïde terrestre par le triplet (LONi,LATi,ALTi) :
Dans la plupart des applications géographiques, on utilise des coordonnées planaires qui sont plus simples à obtenir (digitalisation d'une planche d'Atlas). Leur utilisation n'est pas gênante lorsque l'étude porte sur une petite portion de la surface terrestre, car celle-ci peut être localement assimilée à un plan. En revanche, si l'étude porte sur un grand espace, il faut être conscient des déformations entraînées par la projection.
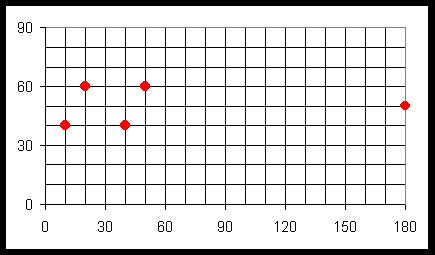
Exemple de tableau des coordonnées :
| i | Xi | Yi |
|
1
|
20
|
60
|
|
2
|
50
|
60
|
|
3
|
10
|
40
|
|
4
|
40
|
40
|
|
5
|
180
|
50
|
Les métriques sont des distances abstraites vérifient
les quatre propriétés suivantes
Les métriques sont imparfaites, en ce sens qu'elles ne donnent que des approximations des distances empiriques que l'on souhaite mesurer. Mais elles ont l'immense avantage d'être beaucoup plus simple à calculer (elle ne dépendent que des coordonnées) et de pouvoir être appliqués à tous couples de points d'un espace. Ainsi, si l'on voulait mesurer la distance-temps entre 1000 lieux différents, il faudrait calculer 1 000 000 de valeurs. En recourant à une métrique, il suffit de connaître les coordonnées des 1000 lieux soit 2000 valeurs, auxquelles on applique chaque fois que nécessaire une fonction - généralement très simple.
La construction d'un grand nombre de métriques permet de choisir
celle qui se rapproche le plus de la distance concrète que l'on
veut étudier.
Définition :
![]()
Exemple :
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Propriétés :
Cette métrique postule que l'espace est homogène et isotrope. Elle introduit donc une simplification de l'espace géographique et ne serait parfaitement valable que pour les déplacements d'un patineur sur un terrain de hockey (pas d'obstacles, aucun itinéraire privilégié, aucune direction privilégiée, etc).
La métrique euclidienne correspond aux distances à vol d'oiseau ; elle sous estime les distances routières d'environ 15 à 30 % à l'intérieur d'un pays comme la France.
Définition :
![]()
Exemple :
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Propriétés :
On peut construire des métriques oblilinéaires ou les deux axes de référence Ox et Oy ne sont pas orthogonaux. Cette solution est particulièrement intéressante lorsque l'on est en présence d'un réseau de transport organisé selon deux directions non orthogonales (ex. région des Appalaches).
métrique radiale
Elle correspond au cas où il est nécessaire de passer par le centre d'un réseau pour se déplacer d'un point à un autre qui n'est pas situé sur le même rayon.
Dr(i,j) = D(i,O) + D(O,j)
métrique périphérique
Elle correspond au cas où il faut éviter le centre et utiliser les voies périphériques. Si les deux points se situent sur des rayons différents il faut parcourir trois tronçons :
1) du point de départ au périphérique
2) sur le périphérique
3) du périphérique au point d'arrivée.
Dp(i,j) = D(i,P1) + D(P1,P2) + D(P2,j)
métrique circumradiale
En général on a la possibilité de choix entre métrique radiale et métrique périphérique. La métrique circumradiale consiste à choisir le minimum des deux solutions possibles.
Dc(i,j) = min [Dr(i,j) ; Dp(i,j) ]
Propriétés :
Ces métriques prennent en compte l'hétérogénéité de l'espace. Elles conviennent bien pour la mesure des distances à l'intérieur d'un espace polarisé par un centre organisateur.En Ile de France, le plus court chemin pour les transports en commun est associé à la métrique radiale alors que pour les transports individuels c'est souvent la métrique périphérique.
Définition :
La métrique orthodromique correspond à l'arc de cercle reliant deux points par le plus court chemin. Si on note (Aij) l'angle exprimé en radians que font ces deux points par rapport au centre de la Terre, la distance orthodromique est égale à
Dij = (Aij/3.1415) * 20000
On suppose que X est la longitude en degrés et Y la latitude en degrés :
Dij=6368*Arccos[(sin(Yi).sin(Yj))+(cos(Yi).cos(Yj).sin(Xi).sin(Xj))+cos(Xi).cos(Xj)]
Exemple :
| Exemple : si on calcule le distances entre les villes
européennes à l'aide d'une projection de Mercator, on va
surestimer les distances entre les villes du Nord par rapport aux distances
entre les villes du Sud :
ex. Oslo (10°E,60°N) et Helsinki (25°E,60°N)
Ces deux couples de villes semblent situés à la même distance sur une projection de Mercator (méridiens et parallèles perpendiculaires) car ils sont situés à la même latitude et avec une différence de longitude de 15°. Mais cette différence de longitude correspond à des distances différentes puisque le diamètre des parallèles se rétrécit : Prague-Kiev = 40000km*(15/360)*cos(50°) = 1071
km
|
Propriétés :
Si l'on néglige l'aplatissement de la Terre aux pôles, cette métrique est à la fois homogène et isotrope.
Applications :
L'utilisation de cette métrique est obligatoire dès lors
que l'on travaille sur de grands espaces pour lesquels une distance euclidienne
appliquée à des coordonnées planaires pourrait entraîner
des distorsions importantes.
Le point moyen non pondéré est le point G dont les coordonnées
sont égales à la moyenne des coordonnées en X (mX)
et la moyenne des coordonnées en Y (mY).
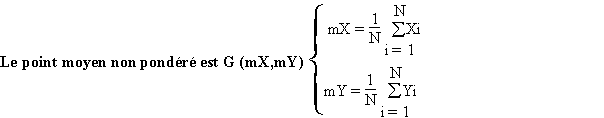
|
Son calcul est extrêmement simple et rapide, toutefois il possède deux limites fondamentales :
Point moyen pondéré :
Lorsque l'on est en présence d'une distribution de population
assimilée à un semis de points valués (X,Y,P), on
peut calculer le point moyen pondéré Gp dont les coordonnées
sont définies par les moyennes de X et de Y pondérées
par P.
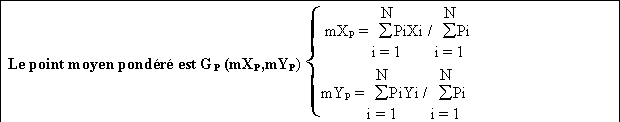
|
Là encore, le calcul est extrêmement simple, mais le point obtenu correspond au centre de gravité de la population et non pas au point le plus accessible pour l'ensemble des membres de la population P.
Applications :
Malgré ses limites, le point moyen a été beaucoup utilisé en géographie pour comparer entre elles les distributions de plusieurs phénomènes à une même date ou d'un même phénomène à différentes dates
Déplacement du point moyen de population en Iowa (1850-1970)

La colonisation de l'Iowa est facilement visualisée et l'on peut remarquer les périodes d'accélération ou de ralentissement du déplacement vers l'Ouest, ainsi que la croissance plus rapide de l'Est à partir de la seconde guerre mondiale. Source : Taylor P.J., 1977. |
Calcul des centres de gravité de différentes productions en Ukraine vers 1926
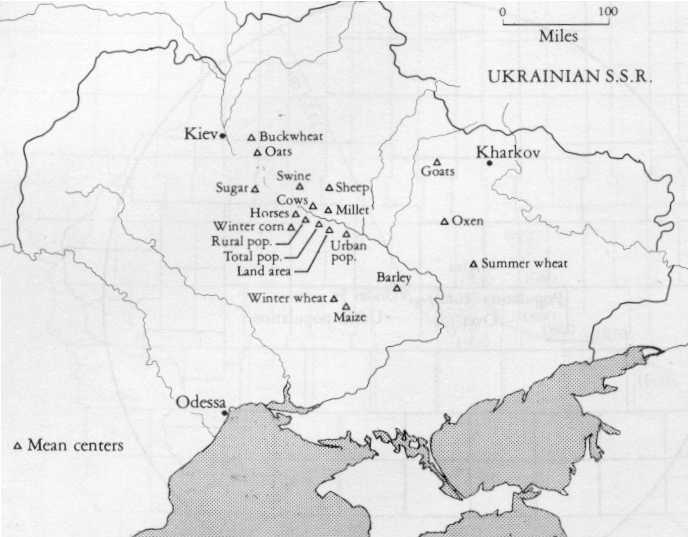
Les géographes soviétiques prétendaient rationnaliser la production en s'efforçant de faire coïncider les différents centres de gravité de production et de consommation ... Après une éphémère heure de gloire, leur centre fut dissous car il proposait des solutions contradictoires avec la volonté du parti communiste ... Source : Taylor P.J., 1977. |
Limites :
Le centre de gravité ne renseigne pas sur la dispersion des points ou de la population autour du centre de référence. Deux populations peuvent avoir un même centre de gravité mais être soit concentrées, soit dispersées autour de celui-ci.
Point médian non pondéré :
Soit un ensemble de points 1..i..N distribués sur un espace E
muni d'une métrique D, le point médian M est le point
le plus accessible, c'est-à-dire celui qui minimise la somme des
distances à l'ensemble de tous les points.
 |
En règle générale, on ne peut trouver le point médian qu'en parcourant tout l'espace E et en calculant à chaque fois l'accessibilité jusqu'à ce qu'on trouve le point qui possède la meilleure accessibilité. C'est notamment le cas en distance euclidienne où il n'existe aucune formule mathématique simple permettant de déterminer le point médian.
Dans le cas particulier de la métrique rectilinéaire (mais dans ce cas seulement), le point médian est facile à déterminer puisqu'il correspond au point M dont les coordonnées sont égales à la médiane de X et à la médiane de Y.
Point médian pondéré :
Dans le cas d'une population P distribuée en N points 1..i..N
de population P1..Pi..Pn, le point médian est celui qui minimise
la somme des distances à l'ensemble de la population.
Comme dans le cas précédent, il n'existe pas de solution mathématique permettant de déterminer rapidement le point médian, sauf dans le cas particulier de la distance euclidienne où le point médian correspond aux médianes pondérées par P de X et de Y.
Dans les problèmes d'aménagement du territoire ou de geomarketing, le point médian définit des localisations optimales au sens de la minimisation du coût moyen de transport ou de relation pour l'ensemble des habitants.
Un exemple célèbre d'application est le problème posé par l'économiste A. Weber pour la localisation d'une entreprise ayant recours à deux inputs et un output localisés en différents points de l'espace.
Limites :
Outre la difficulté de son calcul, le point médian possède un certain nombre d'inconvénients dans les situations réelles. Il n'est en effet pas toujours judicieux de localiser un équipement en rase campagne et l'on préférera souvent choisir une localisation existante plutôt qu'une localisation théorique.
Il arrive également que l'on cherche à localiser plusieurs
équipements pour desservir une population , ce qui définit
un problème de p-médiane : définir l'emplacement
de p équipements minimisant la somme des distances des habitants
à l'équipement le plus proche.
Tout comme une valeur centrale est précisée par un
paramètre de dispersion statistique, un point central doit être
accompagné d'un paramètre de dispersion spatiale qui indique
l'éloignement des points ou de la population par rapport à
celui-ci. On utilisera des paramètres différents selon que
l'on a retenu comme point central le point moyen ou le point médian.
Formule de calcul :
Calcul non pondéré
Le paramètre de dispersion associé est la distance-type
sDqui
est la racine carré de la moyenne du carré des distances,
cest-à-dire la racine carrée de la somme des variances de
X et de Y.
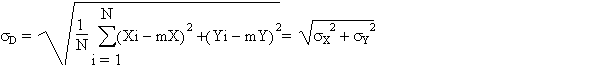 |
Calcul pondéré
Le paramètre de dispersion associé est la distance-type
pondérée sD,P qui
est égale à la racine carrée de la moyenne du carré
des distances à tous les membres de la population P. Si on note
sX,P
lécart type de X pondéré par P et sY,P
lécart type de Y pondéré par P, on a :
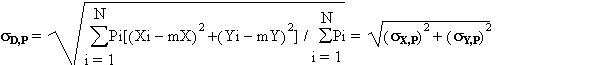 |
Exemple d'application :
Evolution de la distance-type en Iowa (1850-1970)
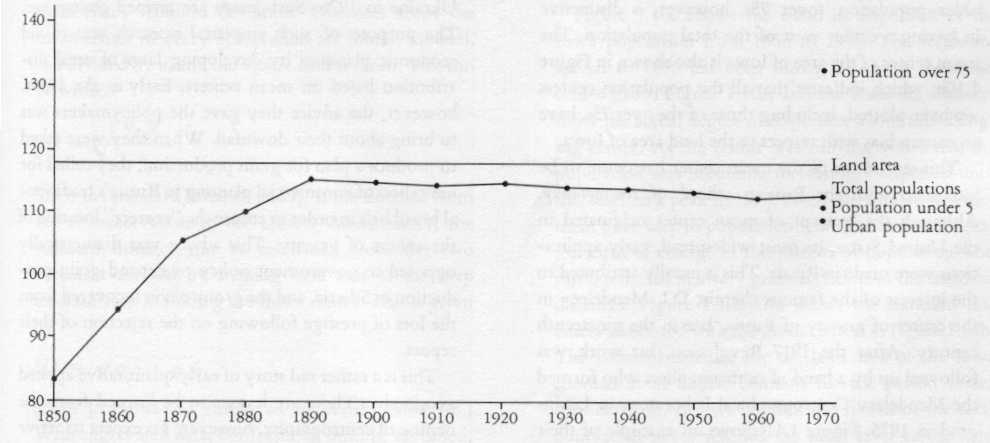
Au fur et à mesure que la population colonise l'Iowa (déplacement vers l'Ouest), elle tend à se disperser de plus en plus sur l'ensemble du territoire de cet Etat. On remarque toutefois en 1970 que la dispersion n'est pas la même pour la population urbaine et la population rurale ou pour les jeunes et les vieux. La dispersion des surfaces (constante) donne une référence commode. Source : Taylor P.J., 1977. |
Exemple : Si l'on étudie la distribution de la population mondiale à la surface de la terre en 1990 en distance orthodormique, le point le plus accessible est situé dans la haute vallée de l'Indus, aux confins du Cachemire et du Tibet. La distance moyenne à l'ensemble de la population mondiale y est de 5150 km.
D0% : distance minimum au point de référence
D50% : distance médiane permettant de totaliser 50 % de la population
autour du point de référence
D100% : distance maximum au point de référence.
On verra dans la partie suivante que cette courbe cumulative d'accessibilité
permet également de calculer des potentiels, c'est-à-dire
des quantités de population en fonction de la distance au point
de référence.
Il arrive fréquemment qu'un semis de point présente
une
distribution concentrique avec une zone de concentration maximale
autour de laquelle les densités décroissent plus ou moins
rapidement. On peut alors chercher à modéliser la distribution
à l'aide d'une courbe indiquant le gradient de densité à
partir du point de concentration maximale.
Exemple théorique : distribution des cratères en fonction de la distance à un point chaud.
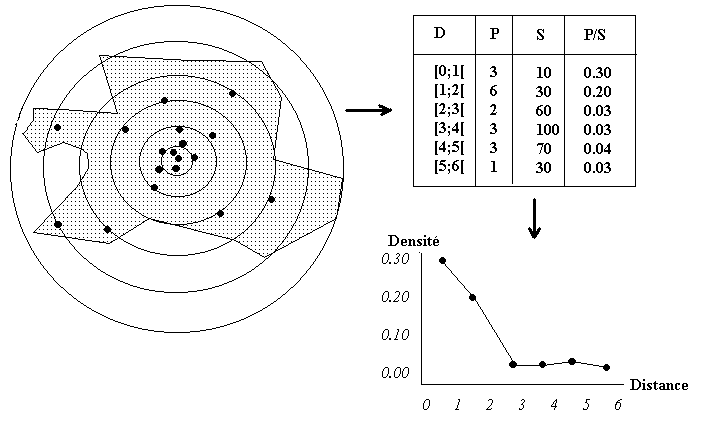
On constate que la densité de cratères diminue entre 0 et 3 km autour du point chaud. Au delà de cette distance, la distribution est uniforme et les cratères doivent être liés à des failles plutôt qu'à une chambre magmatique active. |
On choisit ensuite une mesure de distance D permettant de calculer l'éloignement de tous les points 1..i..N par rapport au centre O. Cette distance peut être une métrique abstraite (euclidienne, rectilinéaire, ) ou une distance concrète (temps de transport, coût de transport, ).
On établit alors k classes de distances d'amplitudes égales[D0; D1]; [D1; D2[ ; [Dk-1; Dk] qui permettent d'évaluer la quantité de population localisée dans chaque intervalle de distance par rapport au point de référence. Ceci permet d'établir un histogramme du nombre de point (ou de la quantité de population) en fonction de la distance P[Di; Di+1]
On en déduit une courbe cumulative Pcum(D) = P[0; D] exprimant la quantité cumulée de point (ou de population s'il s'agit d'un semis pondéré) en fonction de la distance.
P(D) = k.D2
On va donc calculer parallèlement l'histogramme de la distribution des surfaces accessibles en fonction de la distance S[Di;Di+1] et la courbe cumulative correspondante Scum[D].
Dans un espace euclidien, cette surface est égale au disque de rayon D, mais il peut arriver que le calcul soit plus complexe parce que certaines surfaces ne peuvent pas accueillir de points (e.g. étendues inhabitables) ou parce que la distance utilisée n'est pas isotrope (e.g. surface définie par des isochrones qui s'étirent le long des axes routiers). .
Dens [Di; Di+1] = P[Di; Di+1] / S[Di;Di+1]
On va alors chercher à résumer la courbe des densités
en fonction de la distance à l'aide de la fonction la plus appropriée
:
| F(D) = Cste : densité uniforme
F(D) = aD+b : fonction linéaire F(D) = exp(-aD+b) : fonction exponentielle F(D) = a. D-b : fonction puissance F(D) = a0 + a1.D +a2.D2 + an.Dn : fonction polynomiale |
| Den(D)= Den(0) . exp(-bD)
avec :
|
Les travaux de Clark portaient sur 36 villes à différentes dates. Ils ont montré que la loi exponentielle négative donnait dans la plupart des cas un excellent ajustement aux données empiriques, malgré quelques difficultés (cratère central de faible densité de population dans le CBD).Il a alors été possibles à ses successeurs d'étudier les variations du paramètre de la fonction de Clarke (densité centrale et gradient) et de montrer des variations selon la taille de la ville, l'ancienneté de l'urbanisation, etc. On a également calculé des gradients nonplus de densité de population mais de densité d'emploi, de services, etc.
Comme tout modèle, la loi de Clarke comporte des résidus qui apportent souvent des renseignements essentiels sur le phénomène étudié.
Ainsi, lorsqu'on applique la loi de Clarke sur la ville de Yaoundé,
on observe une densité beaucoup plus faible que prévue dans
le centre (même en tenant compte de l'effet cratère). Cette
très faible densité du centre correspond à l'ancienne
"ville blanche" de l'époque coloniale où les indigènes
étaient exclus. Ceux-ci se sont installés à quelques
kilomètres du centre dans des quartiers (Briquetterie, Mokolo,
)
où la densité est vite devenue considérable. Après
la décolonisation, le centre ne s'est pas densifié car il
a été réutilisé par l'administration et le
pouvoir politique pour y installer le CBD.
(a) Distribution de la population de Yaoundé en fonction de
la distance au centre en 1987
|
|
Surface | Population en 1987 |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
N.B. Les calculs sont effectués à laide du centroïde des chefferies : cest pourquoi la croissance des surfaces nest pas régulière.
(b) Forme de la décroissance de la densité de population
en fonction de la distance au centre à Yaoundé en 1987
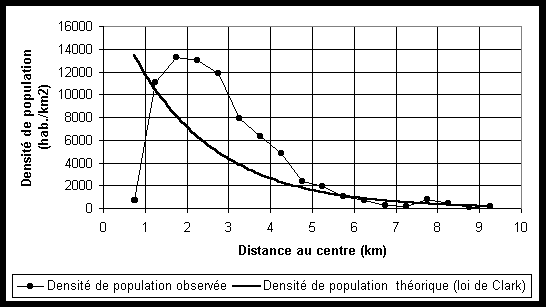
L'ajustement des données à la loi de Clark est très imparfait en raison de la forme très accentuée du cratère de basses densités du centre-ville. Le centre-ville correspond à l'ancienne ville "blanche", autrefois interdite aux autochtones, et toujours réservée actuellement aux bâtiments administratifs ou de prestige. Le pic de densité (vers 2 km) correspond aux anciens noyaux de peuplement indigènes de l'époque coloniale (Mokolo, Briquetterie, etc.). Source : Bopda A., 1997, Yaoundé dans la construction nationale au Cameroun : territoire urbain et intégration, Thèse, Université Paris 1, 2 vol.; |
Exemple théorique : localisation de nouveaux logements par rapport à une voie express
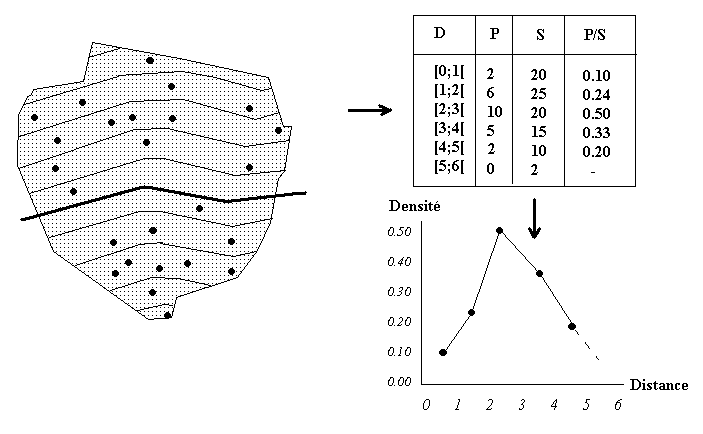
Dans cet exemple théorique, on suppose que l'on examine l'implantation des nouveaux logements dans une commune après l'arrivée d'une voie express. On constate que les habitants se localisent de préférence à 2-3 km pour bénéficier d'un bon accès à la voie express sans pour autant en subir les nuisances (courbe des densités en forme de cloche). |
Les applications sont innombrables :
On peut enfin calculer des distributions de densités sur
l'ensemble d'une surface, sans utiliser des points d'appuis particulier
grâce à la méthode des voisinages ou des fenêtres
mobiles.
La méthode la plus simple est celle du cercle de rayon R que l'on promène en tout point i de l'espace d'étude pour déterminer le potentiel de population (quantité de population contenue dans le cercle de rayon R), le potentiel de surface (quantité d'espace contenue dans le cercle de rayon R) et la densité moyenne (rapport entre le potentiel de population et le potentiel de surface contenus dans le cercle) . On peut alors produire des cartes multiscalaires de densité qui seront plus ou moins généralisées selon le diamètre R du cercle qui aura été utilisé pour calculer les densités.
Pour en savoir plus :
Consulter le site "hypercarte"
Voir les exemples d'application en géographie
du monde
Des méthodes beaucoup plus sophistiquées peuvent être développées pour étudier la répartition des densités dans l'espace (séries de Fourier, lissage gaussien, ) mais elles dépassent largement le cadre de cet enseignement d'initiation aux méthodes d'analyse spatiale.
Le choix qui est ainsi fait de privilégier la distribution uniforme peut être critiqué car pour beaucoup de phénomènes la distribution uniforme est totalement improbable (population, volcans, etc). On peut alors se demander l'intérêt qu'il y a à mesurer l'écart à un modèle dont on sait pertinemment qu'il n'est pas valide.
Le principe des deux méthodes qui vont être étudiées maintenant consiste précisément à ne pas fixer a priori la forme du modèle théorique correspondant à la distribution observée. On va chercher au contraire à déterminer, parmi plusieurs modèles théoriques possibles, celui qui s'ajuste le mieux à la distribution observée. Cette façon de procéder présente deux intérêts majeurs :
1) On passe du cadre de la simple description au cadre inférentiel. La réalisation d'un test permet de savoir si l'ajustement de notre distribution à une distribution théorique donnée est acceptable ou non pour un risque d'erreur donné. Les propositions initiales du type "La distribution est concentrée/aléatoire/régulière" sont falsifiables (au sens de K.R. POPPER - Cf. Chapitre 1).
2) Le fait de montrer l'adéquation entre la distribution observée
et un modèle théorique permet de préciser des hypothèses
sur la nature du phénomène qui a généré
le semis de point.
Adoptons une approche déductive et tentons de déterminer
la forme d'une distribution en fonction du processus qui l'a engendré.
On va considérer pour cela un espace composé de 16 carreaux
de superficie égales (parcelles agricoles, blocs d'habitations,
) où l'on dénombre l'apparition d'objets ou d'événements
qui se mettent en place de façon successive et non pas simultanée.
m : nombre total de points distribués dans l'ensemble observé.
d = m/n : probabilité qu'un point tombe dans un carré donné.
Px : probabilité qu'un carré compte x points
Px = e-d.dx /(x!)
e = 2.71828 est la base du logarithme néperien
Exemple :
| Soit un espace comportant 48 points, divisé en 16
carrés => d=3
- la probabilité qu'un carré comporte 0 points est de 5.0% - la probabilité qu'un carré comporte 1 points est de 14.9% - la probabilité qu'un carré comporte 2 points est de 22.4% - la probabilité qu'un carré comporte 3 points est de 22.4% - la probabilité qu'un carré comporte 4 points est de 16.8% - la probabilité qu'un carré comporte 5 points est de 10.1% - la probabilité qu'un carré comporte 6 points est de 5.0% - la probabilité qu'un carré comporte 7 points est de 2.2% - la probabilité qu'un carré comporte 8 points est de 0.8% - la probabilité qu'un carré comporte plus de 8 points est de 0.4% |
Un indice simple permettant de déterminer si l'on est en présence d'une distribution aléatoire consiste à comparer la moyenne et la variance des densités en calculant le rapport varaiance/moyenne :
Signification du rapport variance/moyenne
| V(d)/d = 1 : distribution aléatoire
V(d)/d > 1 : tendance à la concentration V(d)/d <1 : tendance à la dispersion |
Tester la forme d'une distribution revient à poser l'hypothèse
que celle-ci est le résultat d'un processus d'un certain type (aléatoire,
concentration, dispersion) et à confronter la distribution observée
à une distribution théorique correspondant à l'hypothèse
choisie. Les distributions binomiales positive et négative étant
relativement complexe, on se limitera dans le cadre de cet enseignement
à confronter les distributions observées à une distribution
aléatoire (distribution de Poisson). On partira donc à chaque
fois de l'hypothèse nulle :
H0 : la distribution observée est le résultat d'un processus aléatoire
Si H0 est rejetée, cela signifiera qu'il existe une tendance significative à la concentration ou à la dispersion des points.
Distribution des églises et chapelles du Comté de Leicester
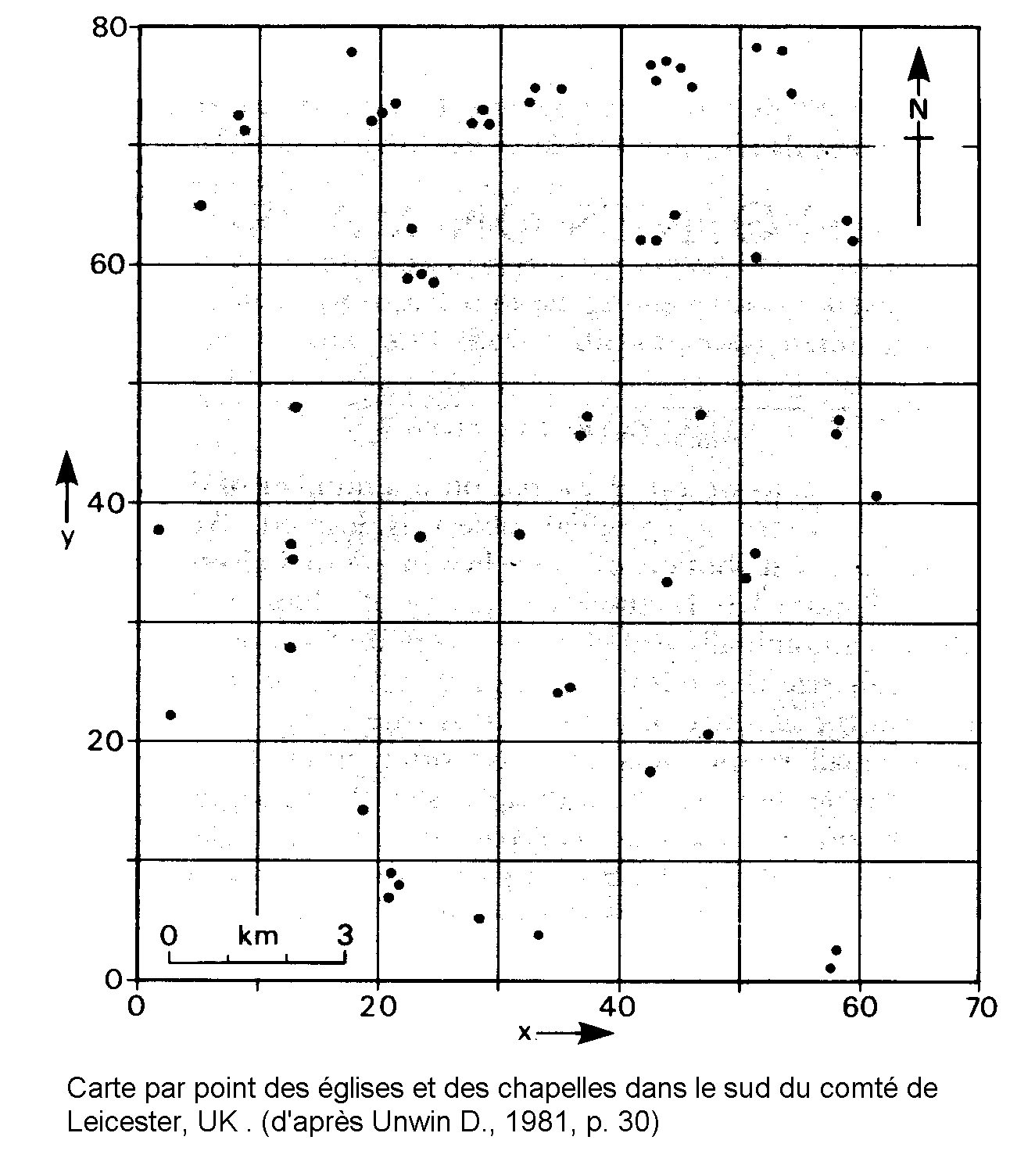 |
Dénombrement de la fréquence des Eglises par carré de 10 km de côté
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Densité moyenne D = nb. de points / nb. de quadrats = 60/56 = 1.071 | ||||
| Variance V(D) = 93.714 / 55 = 1.704 | ||||
| Indice de concentration IC = V(D)/D= 1.590 | ||||
(2) Calcul de l'indice de concentration
La seconde étape de l'analyse consiste à examiner la forme de la distribution des fréquences de points par carreaux et à déterminer si elle se rapproche plutôt d'une distribution aléatoire, concentrée ou régulière. Pour cela, on dispose d'un indice très simple qui est le rapport entre la densité moyenne de points par carreaux (D) et la variance de cette densité V(D). On sait en effet (Cf. supra) que le rapport variance/densité tend vers 1 dans le cas d'une distribution aléatoire.
Dans l'exemple des chapelles du comté de Leicester, ce rapport
est de 1.59 ce qui signale une tendance assez marquée à
la concentration des chapelles en certains points du territoire. La variance
est en effet élevée parce qu'il y a quelques carreaux très
plein et beaucoup de carreaux vides.
![]()
Exemple : Sachant que la densité moyenne est D=1.071 points par carreaux, on peut déterminer la probabilité qu'un point contienne 0 points (34.3%) et en déduire le nombre théorique de carreaux devant contenir 0 points (56 * 0.343 = 19.2).
Ces calculs sont effectués pour toutes les fréquences observées, la probabilité ou la fréquence de la dernière classe (3 et + ) étant déduite par soustraction.
Fréquences observées et théoriques du nombre
de chapelles par carreau
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Confirmant les observations précédentes, on remarque qu'il y a un excédent de carrés plein (3 et +) ou vide (0) et un déficit de carrés contenant un nombre moyen de chapelles (1 ou 2). Ceci est typique d'une distribution concentrée.
Calcul du Chi-2 de l'écart entre fréquences observées et théoriques des chapelles
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Dans l'exemple des chapelles, on obtient un Chi-2 de 5.531 pour 3 degrés de liberté (nombre de classes moins une). Or, l'analyse de la table des valeurs théoriques du Chi-2 pour 3 degrés de liberté montre que cette déviation n'a rien d'exceptionnel :
Extrait de la table du Chi-2
| Chi2 (3, 0.01) = 11.34 |
| Chi2 (3, 0.05) = 7.82 |
| Chi2 (3, 0.10) = 6.25 |
| Chi2 (3,0.20) = 4.64 |
Les déviations observées ont entre 10% et 20% de chances
de se produire dans le cas d'une distribution aléatoire, ce qui
signifie qu'on aurait 10 à 20% de chances de se tromper si l'on
affirmait que la distribution observée n'est pas aléatoire.
Sachant qu'en sciences sociales on se fixe généralement un
seuil de décision de 5%, on doit conclure ici que "la distribution
observée n'est pas significativement différente d'une distribution
aléatoire". Cela ne signifie pas que les chapelles se soient
disposées au hasard, car la loi de Poisson peut être le résultat
de causes multiples agissant dans des directions différentes. Mais
en tout état de cause on ne peut pas affirmer que les chapelles
aient eu tendances à se regrouper ou se disperser en certains points
du comté de Leicester.
Il convient de remarquer que la méthode des quadrats n'est pas exempte de faiblesse. Le choix de la taille et de la forme des carreaux peut en effet entraîner des conclusions différentes pour une même distribution. Ceci peut dans certains cas révéler des problèmes d'échelle, une distribution pouvant être concentrée à l'échelle locale et dispersée aux échelles supérieures (ou l'inverse).
Pour une discussion plus approfondie de ce point, Cf. Taylor P.J., 1977, pp. 146-149.
(1) Principe général de la méthode du plus proche voisin
(a) Soit un semis de N points distribués sur un espace de surface S. On note d la densité moyenne de points par unité de surface à lintérieur de lespace considéré (d=N/S)
(b) On calcule pour chaque point i la distance Dmin(i) qui le sépare de son voisin le plus proche.
(c) On calcule ensuite la moyenne des distances observées au plus proche voisin DO
(d) On détermine la distance théorique moyenne au plus proche voisin DT dans le cas dune distribution aléatoire à laide de la formule :
![]()
( e) On calcule lindice de dispersion qui est le rapport entre ces deux distances :
R=DO/DT
La valeur de cet indice permet de se faire une idée de la forme
de la distribution, sachant qu'il varie entre 0 (concentration totale)
et 2.149 (dispersion maximale selon une grille hexagonale).
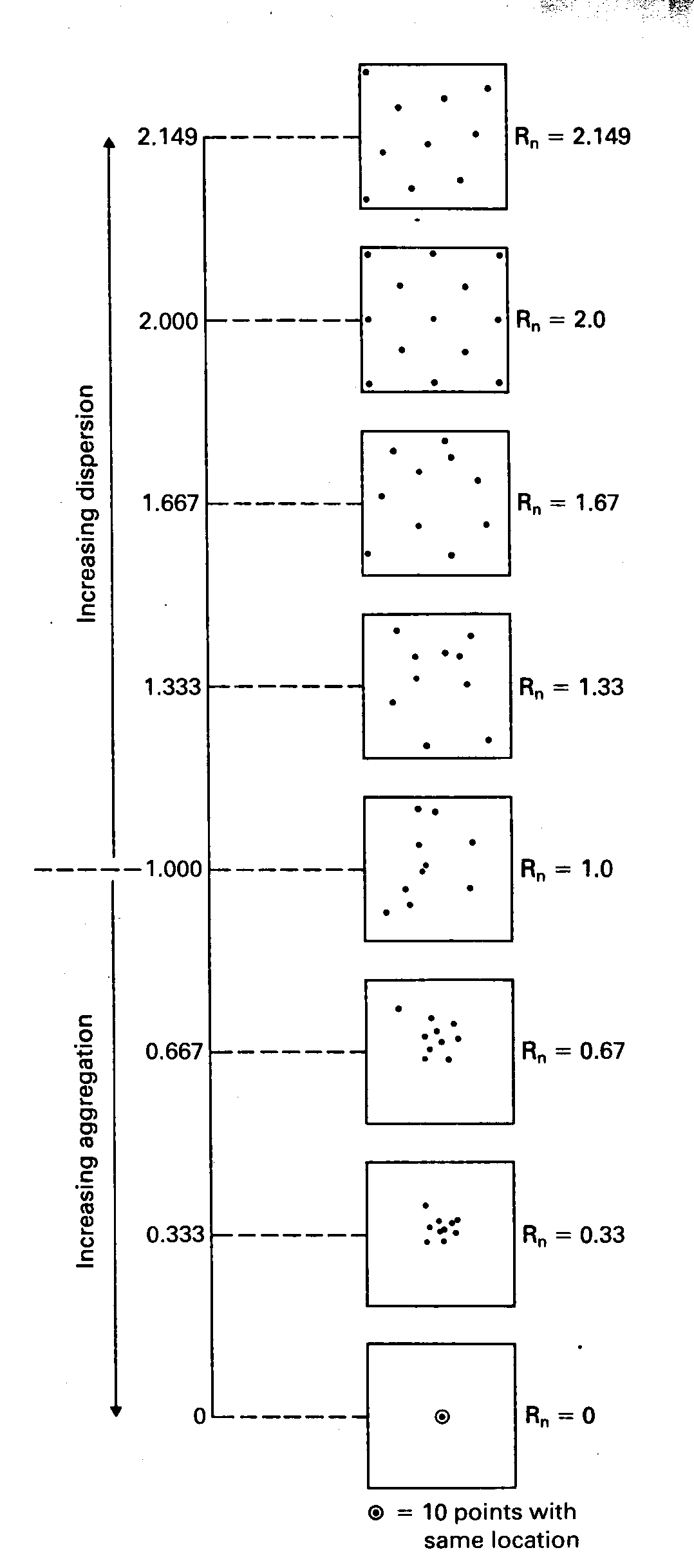 |
(f) Enfin, on peut tester le caractère aléatoire de la distribution à laide dun test paramétrique qui dépasse le cadre de la licence mais peut être trouvé dans tous les (bons) manuels d'analyse spatiale
(2) Exemple d'analyse du plus proche voisin (données théoriques)
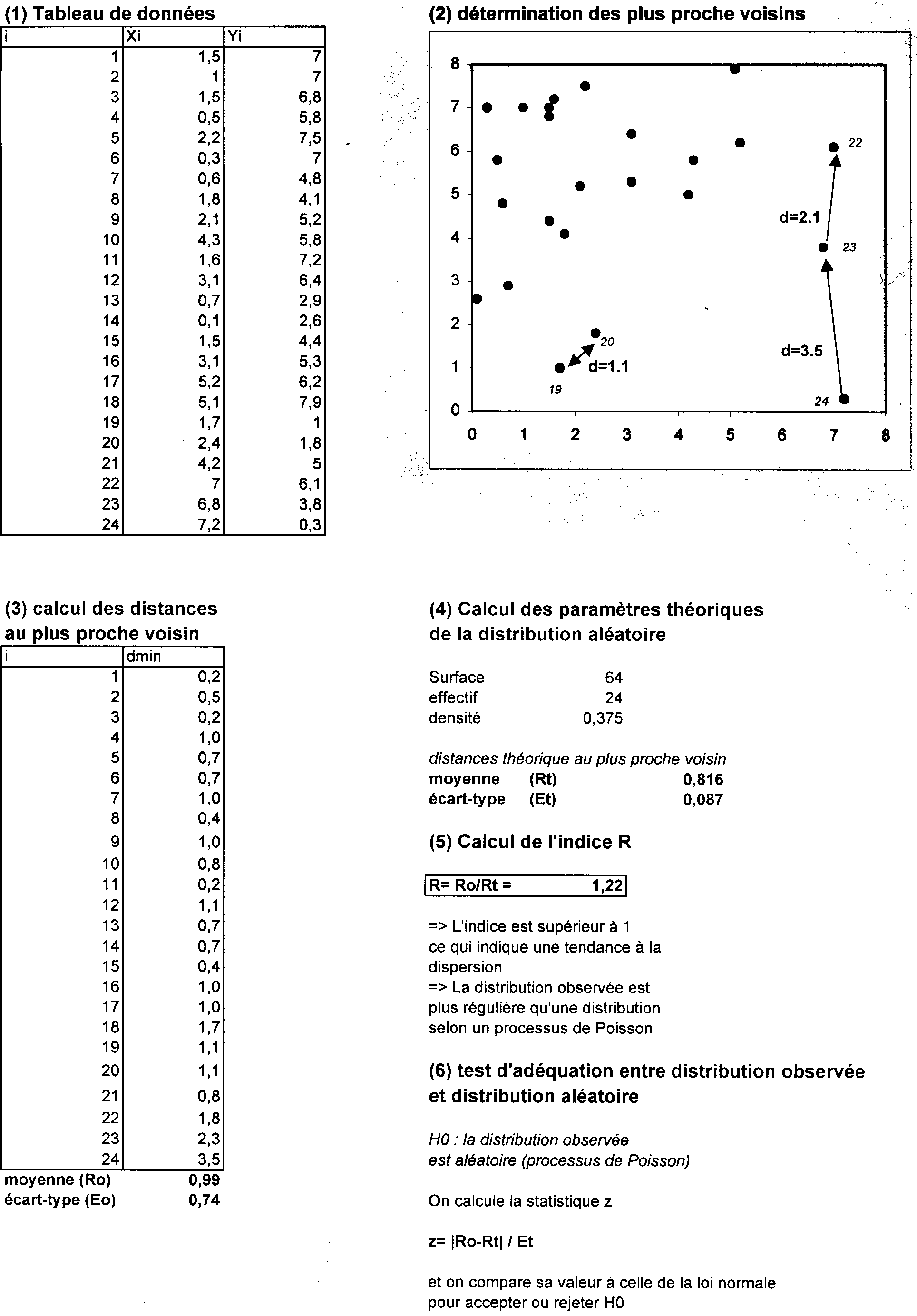 |
(3) Critique de la méthode du plus proche voisin
Tout comme la méthode des quadrats, la méthode du plus proche voisin possède un certain nombre de défauts et de limites, qui peuvent être partiellement résolus.
Malgré leur caractère relativement abstrait, les méthodes
d'analyse des semis de points constituent un élément essentiel
de toute démarche d'analyse spatiale et beaucoup de méthodes
qui seront vues par la suite (analyse de réseaux, de surfaces, de
diffusion,
) ne peuvent être pleinement comprise que si l'on a parfaitement
intégré les notions de ce premier chapitre.
Quant aux difficultés proprement statistique (test d'une distribution aléatoire) elles ont été volontairement simplifiées, mais l'étudiant aura tout intérêt à les approfondir par lui-même car elles sont la base d'une approche scientifique des formes spatiales. Ainsi, c'est en recourant à des tests statistiques très poussés que le géographe S. Oppenshaw a pu démontrer le caractère dangereux de la centrale nucléaire de Sellafield (concentration anormale de Leucémie) contre l'opinion rassurante du ministère britannique de la santé. Il a même découvert au cours de ses recherches un foyer épidémiologique dangereux dont tout le monde ignorait l'existence (incinérateur fonctionnant à trop basse température et libérant de la dioxine).