Chapitre 7 : LA REGRESSION LINEAIRE
|
|
|
|
INTRODUCTION
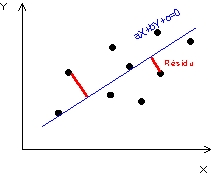
Dans le cas particulier où l'on a pu mettre en évidence l'existence d'une relation linéaire significative entre deux caractères quantitatifs continus X et Y, on peut chercher à formaliser la relation moyenne qui unit ces deux variables à l'aide d'une des trois équations suivantes :(1) a.X + b.Y + c = 0 : équation de la droite
moyenne liant les caractères X et Y
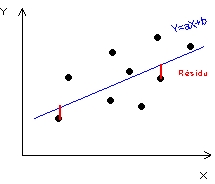
(2) Y = a.X + b : droite de régression de Y en fonction de
X
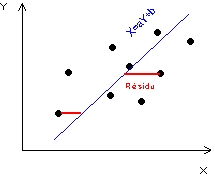
(3) X = a.Y + b : droite de régression de X en fonction de
Y
Les trois équations proposées ci-dessus correspondent à trois droites différentes, trois résumés différents du nuage de points (X,Y). La différence entre les trois droites vient du fait que les trois équations proposées correspondent à trois objectifs différents :
(1) La droite moyenne est un résumé de la relation entre X et Y qui n'introduit aucune hypothèse particulière sur le sens de la dépendance causale qu'il peut y avoir entre les deux variables. Elle visera donc à tracer la droite qui soit la plus proche de tous les points, c'est-à-dire les résidus définis par la perpendiculaire de chaque point à la droite moyenne (plus court chemin).
(2) La droite de régression de Y en fonction de X introduit l'hypothèse que les valeurs de Y dépendent de celles de X, c'est-à-dire postulent que la connaissance des valeurs de X permet de prévoir les valeurs de Y. Il s'agit donc d'un modèle de prévision et l'objectif est de minimiser l'erreur de prévision c'est-à-dire la distance entre les valeurs Yi observées et les valeurs Y*i estimés par la relation Y*=aX+b. Les résidus seront donc la distance à la droite par rapport à l'axe Oy.
(3) La droite de régression de X en fonction de Y introduit l'hypothèse inverse que les valeurs de X dépendent de celles de Y, c'est-à-dire postulent que la connaissance des valeurs de Y permet de prévoir les valeurs de X. Il s'agit donc cette fois-ci de minimiser l'erreur de prévision sur X c'est-à-dire la distance entre les valeurs Xi observées et les valeurs X*i estimés par la relation X*=aY+b. Les résidus seront donc la distance à la droite par rapport à l'axe Ox et non plus par rapport à l'axe Oy comme dans le cas précédent.
Figure 1 : Trois manières différentes de résumer un nuage de point
| (1) Droite exprimant la relation moyenne entre X et Y | (2) Droite exprimant Y
en fonction de X |
(3) Droite exprimant X
en fonction de Y |
 |
 |
 |
Comme on peut le voir sur la Figure 1, les droites de régression linéaire obtenues seront différentes en fonction de l'hypothèse faite sur la relation entre X et Y et la présence ou non d'une dépendance entre les ceux caractères. Il convient donc de toujours spécifier l'hypothèse qui est faite avant d'entreprendre le calcul d'une droite de régression.
Dans le cadre de ce chapitre on se limitera au 2 derniers cas, c'est-à-dire
aux situations où l'on cherche à exprimer non pas la relation
entre
les deux caractères X et Y mais la dépendance d'un
caractère par rapport à un autre (X en fonction de Y ou Y
en fonction de X). Il s'agit donc d'une modélisation à visée
prédictive
puisque l'on suppose que la connaissance de l'une des variables (appelée
variable
indépendante) permet d'estimer la valeur de l'autre variable
(appelée variable dépendante).
7.1 LE CALCUL DE LA DROITE DE REGRESSION Y=aX+b
Un exemple pédagogique de régression linéaire
Pour rendre les choses plus claires, nous partirons d'un exemple
simple et très classique qui est celui de la relation entre l'altitude
(X) et température (Y) à l'intérieur d'une région
de taille suffisamment petite pour que l'on puisse négliger les
facteurs de variations macroscopiques de la température (distance
à la mer, latitude, etc.). Les données présentées
sur la Figure
2 sont imaginaires mais elles pourraient correspondre à la situation
d'une vallée alpine de direction nord-sud pour laquelle on a procédé
au relevé des températures à midi dans huits stations
situées à des altitudes différentes et localisées
sur chacun des versants de la vallée.
Figure
2 : Température et altitude dans 8 stations d'une vallée
alpine (données imaginaires)
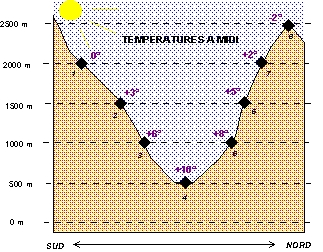
Les données relatives à l'altitude et la température des 8 stations peuvent être rassemblées dans un tableau (tableau 1) à partir duquel on calculera les paramètres caractériques de chaque variable (moyenne et écart-type) ainsi que leur covariance. Pour le détail de ces calculs et les formules correspondantes, se reporter aux chapitres 3, 4 et 6.
Tableau 1 : Paramètres caractéristiques de la température (Y) et de l'altitude (X) de 8 stations météorologiques d'une vallée alpine (données imaginaires)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
On déduit de la valeur de la covariance (-2250) et de celle des deux écarts-type (612 pour X et 3.8 pour Y) l'existence d'une très forte corrélation linéaire négative entre les deux variables :
r(X,Y) = Cov(X,Y) / [ect(X) * ect(Y)] = -2250 / (612 * 3.8) = -0.97.
Même si l'on tient compte du nombre réduits d'observation (8 stations météorologiques soit 7 degrés de liberté) cette corrélation apparaît hautement significative : il y a moins d'une chance sur 1000 que le hasard ait pu engendrer une corrélation aussi forte entre les deux variables X et Y. La forme du nuage de point croisant les valeurs de X et de Y est par ailleurs parfaitement linéaire (Cf. Figure 3) ce qui justifie la recherche d'un ajustement à l'aide d'une droite.
Il reste à déterminer le sens de la relation, c'est-à-dire
l'hypothèse faite sur la variable explicative (indépendante)
et la variable à expliquer (dépendante). Dans l'exemple choisi,
il paraît assez naturel de supposer que la température (Y)
dépend de l'altitude (X) et non pas l'inverse, de sorte que l'on
va chercher à la température Y en fonction de l'altitude
X. Mais la détermination de la relation inverse ne serait pas totalement
absurde et l'on pourrait imaginer ... qu'un alpiniste se serve d'un thermomètre
pour déterminer l'altitude à laquelle il se trouve (en supposant
que les conditions climatiques soient "normales" et qu'il n'y ait pas ce
jour là de phénomène d'inversion thermique).
Détermination de la droite de régression par le critère des moindres carrés
Dans l'exemple très simple qui est proposé, on devine facilement le tracé de la droite de régression qui donnera le meilleur ajustement des températures en fonction de l'altitude (Figure 3) mais il faut se munir d'un critère objectif pour démontrer que la solution proposée est bien la solution optimale, critère que l'on pourra ensuite appliquer à des nuages de points plus complexe où la détermination de la droite de régression optimale est moins évident.Figure
3 : Droite de régression exprimant la température en fonction
de l'altitude pour 8 stations météorologiques d'une vallée
alpine (données imaginaires)
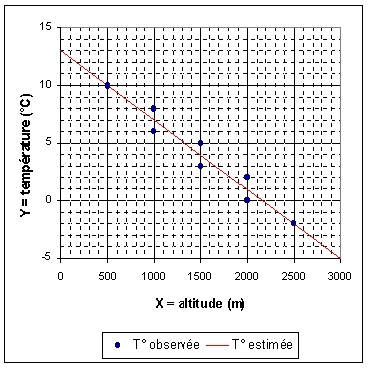
Nous avons vu en introduction que lorsque l'on cherche à exprimer
Y en fonction de X, on peut affecter à chaque valeur observée
Yi
une
valeur estimée par la droite de régression
Y*i
=
aXi+b. L'erreur d'estimation sur l'individu i est donc égal
au résidu eidéfini
par :
| ei = (Yi - Y*i ) = Yi -( aXi+b) |
Comme on souhaite obtenir un ajustement global qui soit optimal pour l'ensemble des stations, il faut définir un critère général définissant la qualité d'ajustement de l'ensemble des valeurs à la droite proposée.
(a) La première solution (ERR1) qui vient à l'esprit est la minimisation de la somme des résidus :
| ERR1 = S ei |
(b) La seconde solution (ERR2) consiste alors évidemment la minimisation de la somme des valeurs absolues des résidus :
| ERR2 = S |ei | |
(c) La troisième solution (ERR3) qui est la plus souvent retenue en statistique est appelée critère des moindres carrés et consiste à minimiser de la somme des carrés des résidus :
| ERR3 = S (ei )2 |
| Les valeurs optimales d'ajustement des paramètres de la droite
Y=aX+b pour le critère des moindres carrés sont données
par les relations :
a = Cov(X,Y) / (sX)2 b = m(Y) - a. m(X) |
Appliquées aux données du Tableau 1, ces équations permettent d'obtenir les paramètres optimaux d'ajustement de la droite de régression de la température en fonction de l'altitude :
a = -2250 / (612*612) = -0.006 (°C / m)
b = 4 - (-0.006 * 1500) = 13 (°C)
On en déduit que l'équation générale donnant la température en fonction de l'altitude dans l'exemple étudié est la suivante :
| Température (°C) = -0.006 * altitude (m) + 13 |
Signification des paramètres de la droite de régression
Le paramètre a de la droite de régression indique de combien varie en moyenne la valeur de Y lorsque celle de X augmente d'une unité. Dans notre exemple, la valeur de a est égal à -0.006 et indique que la température diminue en moyenne de 6 ° C chaque fois que l'altitude augmente de 1000 mètres. Le paramètre a correspond donc à ce que les climatologues appellent le gradient thermique dans une atmosphère stable (pas de phénomène d'inversion thermique). D'un point de vue géométrique, la valeur de a correspond à la pente de la droite de régression par rapport à l'axe Ox.Le paramètre b de la droite de régression correspond quant à lui à la valeur théorique de Y lorsque la valeur de X est égale à 0. Dans notre exemple, il s'agit donc de la température estimé pour une altitude nulle, c'est-à-dire de ce que les climatologues appellent la température ramenée au niveau de la mer. D'un point de vue géométrique, la valeur de b correspond à la coordonnée verticale de l'intersection entre la droite de régression Y=aX+b et l'axe Oy.
L'interprétation empirique des paramètres a et b dépend évidemment de la nature des variables X et Y mises en relation, mais les principes définis précédemment demeurent valable en tout état de cause : a est le taux de variation de Y en fonction de X et b est la valeur de Y pour X =0.
Ainsi, dans le cas d'une régression temporelle du type Y(t)=a.t+b,
le paramètre a correspond au taux moyen de croissance (variation
de Y par unité de temps) et b à la valeur de Y au
temps t=0.
Mesure de la qualité d'ajustement d'une régression linéaire
Un avantage certain du critère des moindres carrés est de fournir une estimation de la qualité d'ajustement d'un modèle de régression fondé sur la décomposition de la variance de la variable dépendante Y.On peut en effet considérer que l'information apportée par une variable Y sur un ensemble d'individus 1..i..N est proportionnelle à la quantité d'écart qui existent entre les différentes valeurs Y1...YN. Si toutes les valeurs étaient égales, l'information serait nulle alors qu'elle sera au contraire d'autant plus élevée que les valeurs diffèrent entre elles. En appliquant le critère des moindres carrés, on va donc considérer que la quantité d'information totale contenue dans une variable Y est proportionnelle à sa variance (sY)2
On peut ensuite décomposer cette quantité d'information
totale (variance de Y) en deux quantités complémentaires
: celle qui peut être reconstituée à partir de la connaissance
de la variable X (variance des valeurs estimées de Y) et celle qui
ne peut être reconstituée à partir de la connaissance
de X (variance des résidus de la régression). Au total,
on peut définir la relation suivante :
| Var (Y)
= Var
(Y*=aX+b) +
Var (e)
information totale = information modélisée + information résiduelle |
La qualité de l'ajustement correspond donc au rapport entre l'information
totale sur Y et l'information effectivement reconstituée à
partir de la connaissance procurée par la variable X. Cette qualité
d'ajustement varie entre 0% (X n'apporte aucun élément de
prévision sur Y) et 100% (la connaissance des valeurs de X permet
de prévoir intégralement les valeurs de Y) et dépend
de l'intensité de la corrélation entre X et Y. Elle peut
se calculer (Tableau
2) ou se mesurer directement à l'aide du coefficient de
détermination, c'est-à-dire du carré du coefficient
de corrélation entre X et Y. Si l'on opte pour le calcul, on constate
que la variance des températures observées (16.2) est bien
égale à la somme de la variance des températures estimées
(15.4) et de la variance des résidus (0.9). La qualité d'ajustement
est donc égal à 15.4/16.2 soit 0.95 ce qui correspond également
au carré du coefficient de corrélation linéaire
des variables X et Y : (-0.97)2 = 0.95 .
| Qualité d'ajustement = Var(Y*) / Var(Y) = [r(X,Y)]2 = coeff. de détermination |
Dans l'exemple étudié, la connaissance de l'altitude permet
donc de prévoir 95% des différences de températures
entre les stations. L'information résiduelle (différences
de température non imputables aux différences d'altitude)
est très faible (5%) ce qui signifie que l'importance des facteurs
autres que l'altitude pouvant générer des différences
de températures entre les stations est extrêmement réduite.
Analyse des résidus d'une régression linéaire
Même si l'importance des résidus d'un modèle de régression est limitée, il est toujours instructif de procéder à leur analyse afin de vérifier :(1) si les résidus ne révèlent pas une mauvaise
spécification du modèle utilisé
(2) si les résidus ne mettent pas en évidence l'existence
d'autres variables explicatives que celle qui a été retenue.
Le premier point sera développé ultérieurement (régression non-linéaire) et l'on va se contenter de développer ici le second à l'aide de l'exemple des températures et de l'altitude.
Tableau 2 : Analyse des résidus de la régression : Température = -0.006 Alt + 13
| i | (Xi) | (Yi) | Y*i=aXi+b | Yi-Y*i |
|
1
|
2000
|
0
|
1
|
-1
|
|
2
|
1500
|
3
|
4
|
-1
|
|
3
|
1000
|
6
|
7
|
-1
|
|
4
|
500
|
10
|
10
|
0
|
|
5
|
1000
|
8
|
7
|
1
|
|
6
|
1500
|
5
|
4
|
1
|
|
7
|
2000
|
2
|
1
|
1
|
|
8
|
2500
|
-2
|
-2
|
0
|
| moyenne |
1500
|
4
|
4
|
0
|
| variance |
428571
|
16.3
|
15.4
|
0.9
|
La somme des résidus est nulle (propriété de la régression linéaire) mais on constate que trois stations ont des résidus positifs (température réelle supérieure de 1° à ce que laisserait prévoir leur altitude) et trois autres des résidus négatifs (température réelle inférieure de 1° à ce que laisserait prévoir leur altitude). Comment interpréter ces écarts ?
On peut tout d'abord supposer que ces écarts sont une composante aléatoire liée à l'imprécision des outils de mesure utilisé (précision des thermomètres) mais dans ce cas là la disposition spatiale des résidus devrait être aléatoire. Or, lorsque l'on cartographie les résidus (Figure 4) on constate que les résidus positifs et négatifs sont loin de se disposer au hasard dans l'espace.
Figure
4 : Configuration spatiale des résidus de la régression :
Température = -0.006 Alt. +13
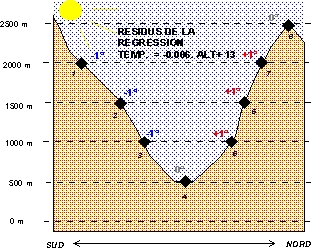
En effet, les résidus positifs se concentrent sur les versants exposés au sud (disposant d'un meilleur ensoleillement) tandis que les résidus négatifs se concentrent sur les versants exposés au nord (disposant d'un ensoleillement plus faible). Les stations situées en fond de vallée ou au sommet des montagnes on au contraire un résidu nul, c'est-à-dire une température rigoureusement conforme au modèle de prévision en fonction de l'altitude.
On en déduit qu'il est possible d'améliorer le modèle de prévision des températures en introduisant une variable qualitative ou quantitative Z qui définit le type d'exposition des stations par rapport à l'ensoleillement dominant et l'on peut envisager de construire un modèle de régression multiple du type Y= a1X+b2Z+c dont la qualité d'ajustement sera meilleure que celle de celui qui ne fait dépendre les températures que de l'altitude. Il convient toutefois de vérifier si l'amélioration apportée par la variable supplémentaire Z est justifiée avant de l'introduire dans le modèle, car la qualité d'un modèle réside autant dans son pouvoir explicatif que dans sa simplicité (principe du rasoir d'Occam).
Ces développements qui relèvent de la régression multiple soulèvent toutefois de nombreuses complications théoriques et statistiques qui ne seront pas développées ici. Pour plus de détails, on peut se reporter à l'article que nous avons publié en 1995 dans la revue pédagogique Feuilles de Géographie :
Grasland C., 1995, "Modélisation et commentaire de documents
: application à l'étude des précipitations en Claifornie
et des migrations entre les villes de plus de 50 000 habitants en France",
Feuilles
de Géographie, IV-1995, n°16, 20 p.
7.2 APPLICATIONS PRATIQUES DE LA REGRESSION LINEAIRE
A travers l'exemple de la relation température/altitude,
on va montrer quelles sont les applications possibles de la régression
en géographie.
Résumer
Problème : supposons que l'on dispose de 100 stations météorologiques en Auvergne, pour lesquelles on mesure l'altitude en mètres (X) et la température moyenne (Y) tout au long de l'année.Est-il réellement utile de retenir chaque jour les 100 températures ?Réponse : l'observation a montré qu'il y avait une forte corrélation négative (-0.90) entre l'altitude et la température. La droite de régression T°C = -0.006.Am+10° permet de résumer l'essentiel de l'information sur la variation spatiale des températures (-0.9*-0.9= 81%), dès lors que l'on connaît l'altitude.
Conclusion : la régression permet de résumer
un ensemble volumineux d'informations à l'aide de deux paramètres.
Ce résumé est évidemment d'autant plus valable que
la corrélation est élevée.
Modéliser
Problème : l'observation répétée tout au long de l'année montre que le coefficient a ne change guère (-0.006) alors que le coefficient b varie selon les saisons (élevé en été et faible en hiver) : que peut-on en déduire ?Réponse : le coefficient a indique de combien varie la température chaque fois que varie l'altitude. Ainsi, une variation d'altitude de +100 m correspond à une diminution de température de -0.006*100 = -0.6°C : c'est le gradient thermique. Le coefficient b indique la t° correspondant au cas ou l'altitude est de 0m : c'est donc la température moyenne ramenée au niveau de la mer.
Conclusion : nous venons de redécouvrir quelques
lois élémentaires de la climatologie.
Prévoir
Problème : si le journal télévisé présente les t° ramenés au niveau de la mer, comment estimer celle de mon village qui se trouve à 800 m ?Réponse : si le journal annonce 15° en Auvergne, l'équation de la droite de régression est du type T°=-0.6.A+15, donc la température sera approximativement de 10° à 800 m d'altitude..
Conclusion : la régression permet d'extrapoler des
résultats obtenus sur un échantillon.
Mettre en évidence des effets secondaires masqués par un effet principal
Problème : si l'équation de la droite de régression est T°=-0.6A+10 sur l'ensemble de l'année (r=+0.90) quelle information est apportée par la cartographie des résidus ?Réponse : les résidus correspondent au 20% de la
variation spatiale des température qui n'est pas déterminée
par l'altitude. Ils mettent donc en évidence des microclimats
liés à l'orientation, la végétation, la topographie,
l'activité humaine, etc. :
- les résidus positifs correspondent aux micro-climats chauds (T° plus élevée que l'altitude ne l'aurait laissé supposer)
- les résidus négatifs correspondent aux micro-climats froids (T° moins élevées que l'altitude ne l'aurait laissé supposer)
- les résidus nuls correspondent à une T° conforme à ce que laissait prévoir l'altitude.
7.3 PROLONGEMENTS DE LA REGRESSION LINEAIRE : LES TRANSFORMATIONS LOGARITHMIQUES
Relativement simple d'utilisation, la régression linéaire
n'est malheureusement pas toujours adaptée à la nature de
la relation qui lie deux caractères X et Y. Nous avons en effet
montré au cours du Chapitre 6
que la relation linéaire constituait un cas particulier de relation
entre deux caractères et qu'il existe de nombreux cas ou la forme
du nauage de point révèle l'existence de relations non-linéaires
voire de relations trompeuses (valeurs exceptionnelles, emboîtement
d'échelles, ...).
Dans la présentation très simplifiée de la régression linéaire que nous avons effectuée ici (destinée à des non-statisticiens) nous avons volontairement omis de préciser de façon détaillée les hypothèses théoriques qui sous-tendent l'emploi de cette méthode et, plus particulièrement du critère des moindres carrés. Mais il est nécessaire que l'utilisateur non-spécialiste de la régression linéaire ait une idée, au moins intuitive, des conditions normales d'utilisation de cette méthode, faute de quoi il risquerait d'aboutir à des conclusions totalement erronées.
De surcroît, il existe un certain nombre de transformation mathématiques
relativement simples (semi-logarithmique ou bi-logarithmique) qui permettent
d'améliorer considérablement les prévisions d'un modèle
de régression linéaire lorsque les hypothèses de bases
de celle-ci ne sont pas respectées. Même si ces solutions
peuvent être considérées comme criticables sous certains
aspects, elles introduisent déjà une amélioration
importante par rapport à un usage non-maîtrisé de la
régression linéaire.
Exemples de spécification incorrecte d'un modèle de régression linéaire
D'une manière générale, l'analyse de la distribution des résidus d'un modèle de régression linéaire permet de détecter assez facilement les cas de mauvaise spécification d'un modèle de régression linéaire et de comprendre de façon intuitive la nature du problème statistique qui interdit son emploi.Distribution "normale" des résidus
Le cas "idéal" sur le plan statistique est celui où les deux distributions X et Y servant de base à la relation ont des distributions de type gaussien et où les points se distribuent de façon "harmonieuse" et "continue" de part et d'autre de la droite de régression. Dans ce cas "idéal", on peut considérer que la variance des résidus (Y-Y*) est constante quelle que soit la valeur de la variable Y et l'on peut construire un intervalle de confiance qui indique le degré de précision des estimations des valeurs de X en fonction de celles de Y. Cet intervalle de confiance sera défini par l'écart-type des résidus et l'on pourra utiliser les propriétés habituelles de l'écart-type (e.g. 95% des valeurs situées à moins de deux écart-type) pour donner un ordre de grandeur à la précision des estimations faites à l'aide de la régression linéaire (Figure 5)Figure 5 : Cas "idéal" de distribution des résidus
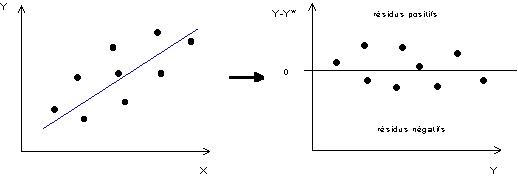 |
Hétéroscédasticité de la distribution des résidus
Lorsque la distribution de X ou celle de Y est non gaussienne on voit fréquemment apparaître des nuages de points où la variance des résidus n'est pas constante et tend à être plus ou moins forte selon l'intervalle de Y considéré. Cette hétérogénéité de la variance des résidus, aussi appelé hétéroscédasticité, est gênante car elle interdit la construction d'un intervalle de confiance, ou tout au moins elle implique le recours à des techniques statistiques beaucoup plus compliquées pour définir celui-ci. Dans l'exemple présenté sur la Figure 6, il existe bien une relation linéaire entre les variables X et Y, mais le nuage affecte une forme en "entonnoir" ce qui signifie que les estimations de Y en fonction de X sont très bonnes pour des valeurs petites de Y mais beaucoup plus médiocres pour des valeurs élevées de Y. L'incertitude relative à l'estimation de Y en fonction de X ne peut donc pas être définie à l'aide d'un seul paramètre comme dans le cas précédent (écart-type des résidus) et il faut utiliser une fonction plus compliquée (comportant ici deux paramètres) pour définir un intervalle de confiance.Figure 6 : Exemple typique d'hétéroscédasticité de la distribution des résidus
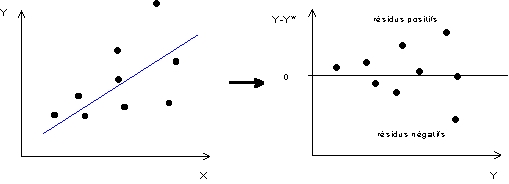 |
=> Dans les cas les plus simples et les plus courants d'hétéroscédasticité
(du type de celui présenté sur la Figure 6), on peut tenter
de résoudre le problème en opérant une transformation
logarithmique de la variable X et/ou de la variable Y, qui conduit généralement
à une distribution beaucoup plus homogènedes écarts
au modèle et où l'on pourra construire un intervalle de confiance
(relatif au logarithme des valeurs de Y et non plus aux valeurs de Y proprement
dites)
Autocorrélation de la distribution des résidus
Nettement plus ennuyeux que le cas précédent est celui où l'on détecte une autocorrélation des résidus, c'est-à-dire un lien entre les valeurs de Y et la distributions des écarts positifs et négatifs par rapport au modèle de régression. Dans l'exemple présenté sur la Figure 7, on constate par exemple que toutes les valeurs moyennes de Y sont sur-estimées par le modèle(résidus négatifs) alors que les valeurs faibles et fortes de Y sont sous-estimées (résidus positifs). La présence d'une autocorrélation des résidus signifie que le modèle linéaire n'est pas adapté à la forme du nuage de point et que la relation liant les deux variables X et Y est plus compliquée (non-linéaire). Une autocorrélation des résidus signifie donc que le modèle est mal spécifié et qu'il existe une forme plus pertinente de description de la relation entre les deux caractères X et Y que l'ajustement à une simple droite.Figure 7 : Exemple typique d'autocorrélation de la distribution des résidus
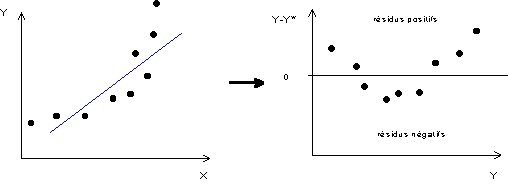 |
=> Dans les cas les plus simples (résidus du type de ceux
présentés sur la Figure 7), le recours à une transformation
semi-logaritmique ou bi-logarithmique suffit dans la plupart des cas à
"redresser" le nuage de point et à éliminer l'autocorrélation
des résidus. Cette solution n'est toutefois pas valable si la distribution
des résidus comporte plusieurs minima ou maxima : dans ce cas, l'ajustement
devra être réalisé à l'aide d'une fonction polynomiale
de X comportant plusieurs termes (du type Y=a1X+a2X2
+
... anXn + b) ou bien à l'aide d'un modèle
de régression multiple introduisant d'autres variables explicatives
que X.
Discontinuités dans la distribution des résidus
Un dernier cas, moin souvent évoqué dans la littérature statistique, mais tout aussi gênant que les deux précédents est celui de la présence d'une discontinuité dans la distribution des résidus, liée à la présence de deux sous-nuages de points nettement dissociés. Ce problème qui est illustré par la Figure 8 a déjà été évoqué au Chapitre 6 à propos des relations emboîtées. Dans le cas d'une régression linéaire, la présence d'une discontinuité dans les résidus implique que l'on ne dispose pas d'information sur une partie de la distribution des valeurs (X,Y), de sorte qu'il est discutable de reconstituer cette zone de la distribution en extrapolant les valeurs de la droite de régression. Il serait plus sage, dans un cas comme celui-ci de construire autant de modèles de régression qu'il existe de sous-nuage de point. On peut alors s'apercevoir que la relation globale disparaît ou change de signe lorsque l'on calcule les paramètres de régression sur chacun des sous-nuages de points.Figure 8 : Exemple typique d'autocorrélation de la distribution des résidus
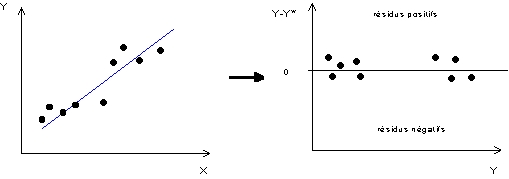 |
Transformations semi-logarithmiques et bi-logarithmiques
Une solution souvent efficace aux problèmes d'autocorrélation et d'hétéroscédasticité des résidus consiste à calculer la régression linéaire non pas sur les variables X et Y mais sur les variables X et log(Y) ou log(X) et log(Y), ce qui correspond respectivement aux modèles d'une relation exponentielle ou d'une relation puissance.Si l'on reprend l'exemple de la taille des pieds et de l'intelligence
des enfants qui a été examiné au cours du chapitre
6, on peut essayer d'estimer la droite de régression linéaire
qui permet d'estimer l'intelligence (Y) en fonction de la taille des pieds
(X). On rappelle que la covariance des deux caractères était
de 64.1 et que les deux variables X et Y avaient respectivement pour moyenne
34 et 76, pour écart-type 2.4 et 32, la valeur du coefficient de
corrélation linéaire étant de +0.83. On en déduit
le modèle suivant :
| Intelligence (Y) = 11.1 * Taille des pieds (X) -302
avec une qualité d'ajustement r2 = 69% |
Puis on calcule les résidus associés :
Tableau 3 : Régression linéaire entre l'intelligence (Y) et la taille des chaussures (X)
| i | X | Y | Y* | Y-Y* |
| A |
31
|
50
|
43
|
7
|
| B |
31
|
55
|
43
|
12
|
| C |
32
|
52
|
54
|
-2
|
| D |
33
|
56
|
65
|
-9
|
| E |
33
|
63
|
65
|
-2
|
| F |
34
|
65
|
76
|
-11
|
| G |
35
|
69
|
87
|
-18
|
| H |
36
|
90
|
98
|
-8
|
| I |
37
|
110
|
109
|
1
|
| J |
38
|
150
|
121
|
29
|
On constate que la construction d'un modèle de régression exprimant l'intelligence (Y) en fonction de la taille des pieds (X) aboutirait à une très forte autocorrélation des résidus (Figure 9)
Figure
9 : relation entre la taille des pieds et l'intelligence : ajustement linéaire
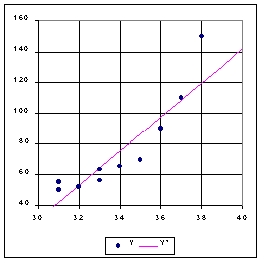
Transformation semi-logarithmique et relation exponentielle
On peut alors tenter de linéariser la relation en cherchant une relation non plus entre la taille des pieds et l'intelligence mais entre la taille des pieds (X) et le logarithme de l'intelligence (log(Y)).On constate immédiatement une amélioration du coefficient de corrélation (+0.95) qui indique que la relation est mieux décrite que précédemment et l'on obtient les paramètres suivants :
log(Y) = 0.14 X -0.49 (r2 = 90%)
On en déduit l'existence d'une relation exponentielle exprimant
Y en fonction de X :
| Intelligence (Y) = 0.61 * exp(0.14* Taille des pieds)
avec une qualité d'ajustement r2 = 90% |
Figure
10 : relation entre la taille des pieds et l'intelligence : ajustement
exponentiel
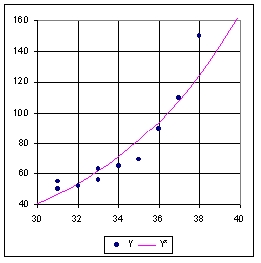
Malgré l'amélioration très nette de l'ajustement,
on constate sur la Figure
10 la persistance d'une autocorrélation des résidus,
ce qui insiste à utiliser une autre forme de modèle.
Transformation bi-logarithmique et relation puissance
On peut en effet chercher une relation le logarithme la taille des pieds log(X) et le logarithme de l'intelligence log(Y), ce qui correspond à une relation de type puissance.Le coefficient de corrélation est un peu moins bon que pour le modèle exponentiel (+0.94) mais cela ne signifie pas obligatoirement que le modèle est moins bon. Il faut en effet examiner si ce nouveau modèle réduit l'autocorrélation des résidus.
log(Y) = 4.74 log (X) -12.4 (r2 = 88%)
On en déduit l'existence d'une relation puissance exprimant Y
en fonction de X :
| Intelligence (Y) = 3.3 * 10 -6 * (Taille des pieds)4.74
avec une qualité d'ajustement r2 = 88% |
Figure 11 : relation entre la taille des pieds et l'intelligence
: ajustement puissance
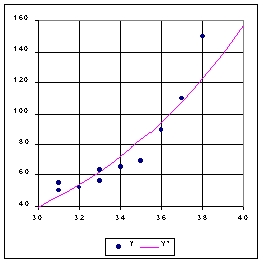
L'autocorrélation des résidus n'est pas réduite
par la transformation puissance et on décidera donc de conserver
l'ajustement exponentiel dont la qualité était meilleure.
Commentaire général
La solution idéale consisterait dans l'exemple étudié
à utiliser une procédure de régression non-linéaire
(plus efficace que les méthodes semi-logarithmiques ou bi-logarithmiques
qui n'en sont que des approximations. Mais cette solution suppose le recours
à des méthodes statistiques plus complexes.
On se bornera à suggérer à l'utilisateur novice
de la régression de calculer systématiquement les trois coefficients
de corrélation suivants r(X,Y), r(X, logY) et r(logX, logY) pour
déterminer le modèle le plus adapté aux variables
qu'ils veut mettre en relation (plus forte qualité d'ajustement).
Même si cette méthode n'est pas exempte de critique, elle
constitue une amélioration sensible par rapport à un recours
systématique à l'ajustement linéaire simple.